DataX – advancing the frontiers of computer vision and natural language processing
by Sharon Adarlo, Center for Statistics and Machine Learning
Over the last several years, researchers have developed advanced machine learning tools to provide captions for still images and video. Applications for advanced image caption tools could include an assistant robot for the visually impaired or a robot that performs reconnaissance missions in environments inhospitable to humans.
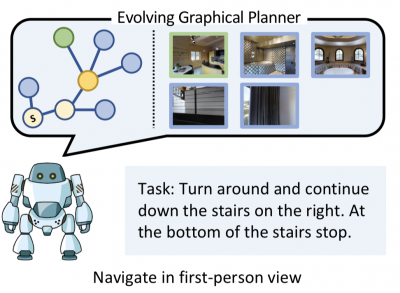
Image from the paper "Evolving Graphical Planner: Contextual Global Planning for Vision-and-Language Navigation." Authors are Zhiwei Deng, Karthik Narasimhan and Olga Russakovsky.
"Our goal is to enable seamless human and machine collaboration where the machine can understand both human speech and the visual appearance of the surrounding world," said Russakovsky.
Towards this goal, the researchers developed three related projects that advance computer vision and natural language processing.
"We hope these improvements will lead to image caption tools that provide descriptions beyond generic terms and open up new applications," said Narasimhan.
This project was one of the first nine funded last year by Princeton University's Schmidt DataX Fund, which aims to spread and deepen the use of data science and machine learning across campus to accelerate discovery. In February last year, the University announced the new fund, which was made possible through a major gift from Schmidt Futures.
"Image and video captioning technologies have become ubiquitous, and that necessitates the creation of methods that ensure that these technologies are performing well," said Peter Ramadge, director of the Center for Statistics and Machine Learning, which oversees parts of the DataX Fund.
The other personnel working on this project include graduate students Felix Yu and Zeyu Wang and postdoc Zhiwei Deng.
To better understand current performance, researchers analyzed a variety of modern captioning systems and associated evaluation metrics. The results are detailed in their paper, "Towards Unique and Informative Captioning of Images," presented at the European Conference on Computer Vision in 2020.
State-of-the-art image captioning models produce generic captions, often leave out important details, and sometimes misrepresent the image. The underlying cause of these deficiencies is that captions are derived from a small set of generalized, common concepts. This results in a captioning model producing the same caption for different images, said Wang. The paper used the example of several distinct photos of people, both men and women, playing tennis on a variety of surfaces, all of which were assigned the caption: "a man holding a tennis racket on a tennis court."
In response, the researchers developed an evaluation metric called SPICE-U, which measures a caption's specificity and descriptiveness. They also produced a method to improve current caption systems, said Wang. Captions enhanced with this method were more descriptive and informative and scored better on SPICE-U versus standard captioning systems.
In their second project, "Take the Scenic Route: Improving Generalization in Vision-and-Language Navigation," the researchers worked on an existing dataset for training robots (or agents) called Room-to-Room (R2R) and pinpointed cues that could lead robots astray. This project was presented at the Computer Vision Pattern Recognition Visual Learning with Limited Labels Workshop in 2020.
An agent trained on R2R showed lower performance when confronting new environments because R2R encodes biases from previous actions undertaken by the agent, also called "action priors." To improve performance issues, the team proposed adding additional machine annotated instructions obtained from random walk paths, resulting in improved performance on new environments.
In a third project, "Evolving Graphical Planner: Contextual Global Planning for Vision-and-Language Navigation," the team sought to develop a navigation algorithm which they then used to guide a robot inside a virtual environment, Deng said. The researchers will present the paper at the Neural Information Processing Systems 2020 conference.
This project's challenge was to merge natural language instructions and the agent's growing knowledge of its environment while planning and making decisions in its walk towards an endpoint, said Deng. Efforts to overcome these challenges have remained limited.
To address these challenges, the team developed a graph-based model "that performs global planning for navigation based on raw sensory input," according to their paper. While the model explores its environment, it adds more information to a graph and connects this incoming information, said Deng. When compared to existing navigation systems, this new model performs better.
"If you think about building these systems, they involve low-level micro-actions that you have to be able to compose. The robot needs to know what a couch and what a paper is," said Narasimhan. "The major aim of all these projects is to merge visual processing with natural language understanding."