 Fraud Detection
Fraud Detection
In this assignment you are going to implement a few algorithms that, when put together, form a machine learning model to detect fraudulent credit card transactions. The model you will implement is a (very) simplified version of one that could be employed in the real world. In this process, you will apply many algorithms you learned throughout this course.
Consider a set of \(m\) points in 2D space, each representing
coordinates of retail establishments, such as shops and restaurants,
on a map. These points are represented using the immutable data
type Point2D
(part of algs4.jar). Below is an example of
locations in a map of Princeton.
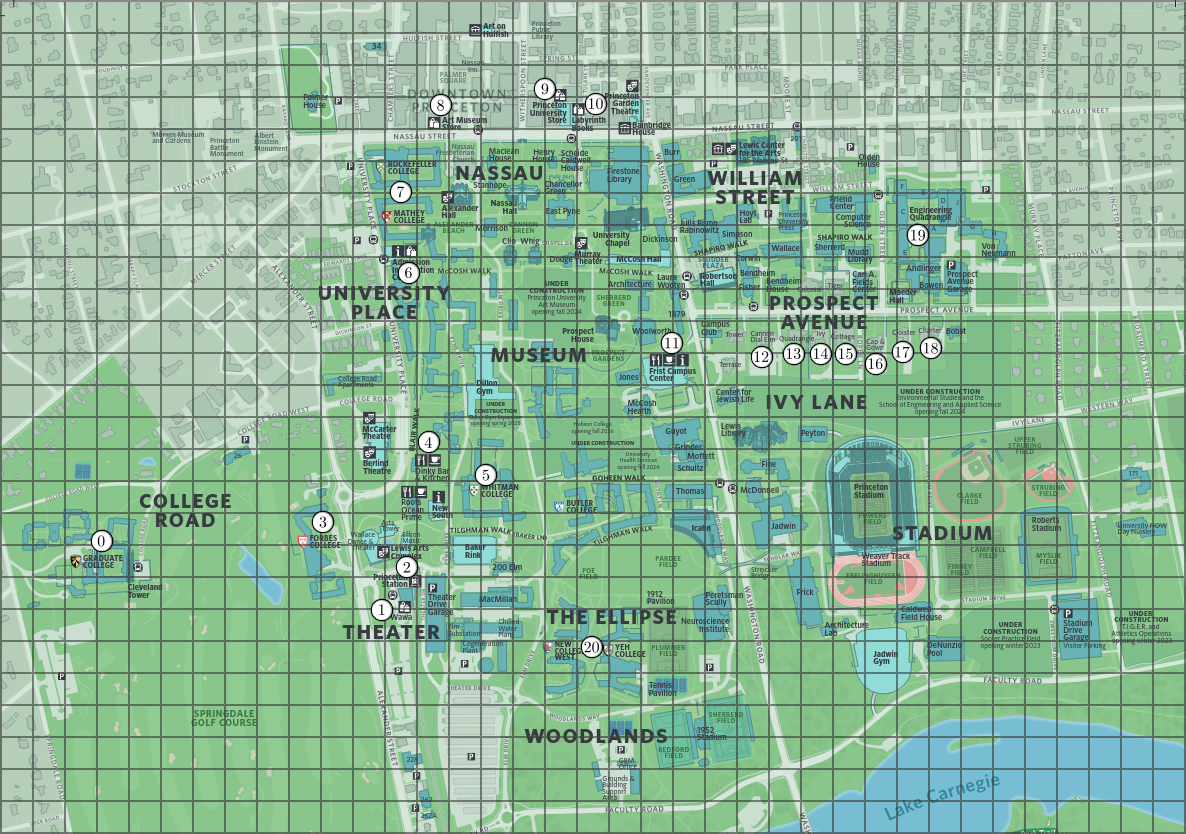
Additionally, you are given a data set with \(n\) labeled
transaction summaries. In your implementation you can assume
\(n\) is always at least 1. A transaction summary is an array of
\(m\) non-negative integers, one per location, representing the
amount of money spent at each location by a particular person. A
label is either clean or fraud,
indicating whether a fraudulent transaction was detected in the
corresponding transaction summary. Here is an example of
one. Each number corresponds to a vertex in the graph (e.g. the
first number represent the amount of money spent at "Graduate
College," the leftmost point).
| 5 | 6 | 7 | 0 | 6 | 7 | 5 | 6 | 7 | 0 | 6 | 7 | 0 | 6 | 7 | 0 | 6 | 7 | 0 | 6 | 7 | clean |
You will create a simple machine learning model that learns from
a data set. This means that you will be given a collection of
labeled transaction summaries and write an algorithm that can
label new transaction summaries as either clean
or Fraud. In your code you will represent these
labels using integers, where \(0\) represents clean
and \(1\) represents fraud.
Before feeding the data into the machine learning model, you
will first reduce the dimension of the input (i.e. the
transaction summaries) using a clustering algorithm. This
algorithm receives \(m\) objects of type Point2D
(representing locations) as well as an integer \(k\), which
represents the number of clusters (\(k\) should be at least 1
and at most \(m\)). The goal is to output a partition of the
points into \(k\) clusters (i.e., groups), such that the points
in the same cluster are similar (in our case, two points are
similar if the Euclidean distance between them is small). Each
cluster should be labeled by an integer between 0 and \(k -
1\). The output format is an array of \(k\) elements, the
\(i\)th of which represents the total amount of money that
transaction summary spent across all locations in the \(i\)th
cluster.
This step is applied not only to make the model more efficient, but it also improves its accuracy by mitigating an overfit of the model to the input data.
Here is what the clustering algorithm should do:
You don't have to implement all these steps from scratch, there
are several helpful classes in algs4.jar that you can use (see the
implementation requirements below).
The following images represent the minimum spanning tree and the clusters obtained from the Princeton locations above, with \(k = 5\) groups/clusters. On the image on the right, the dashed lines represent the edges of the minimum spanning tree that are not in the new graph and the clusters are indicated by colors.
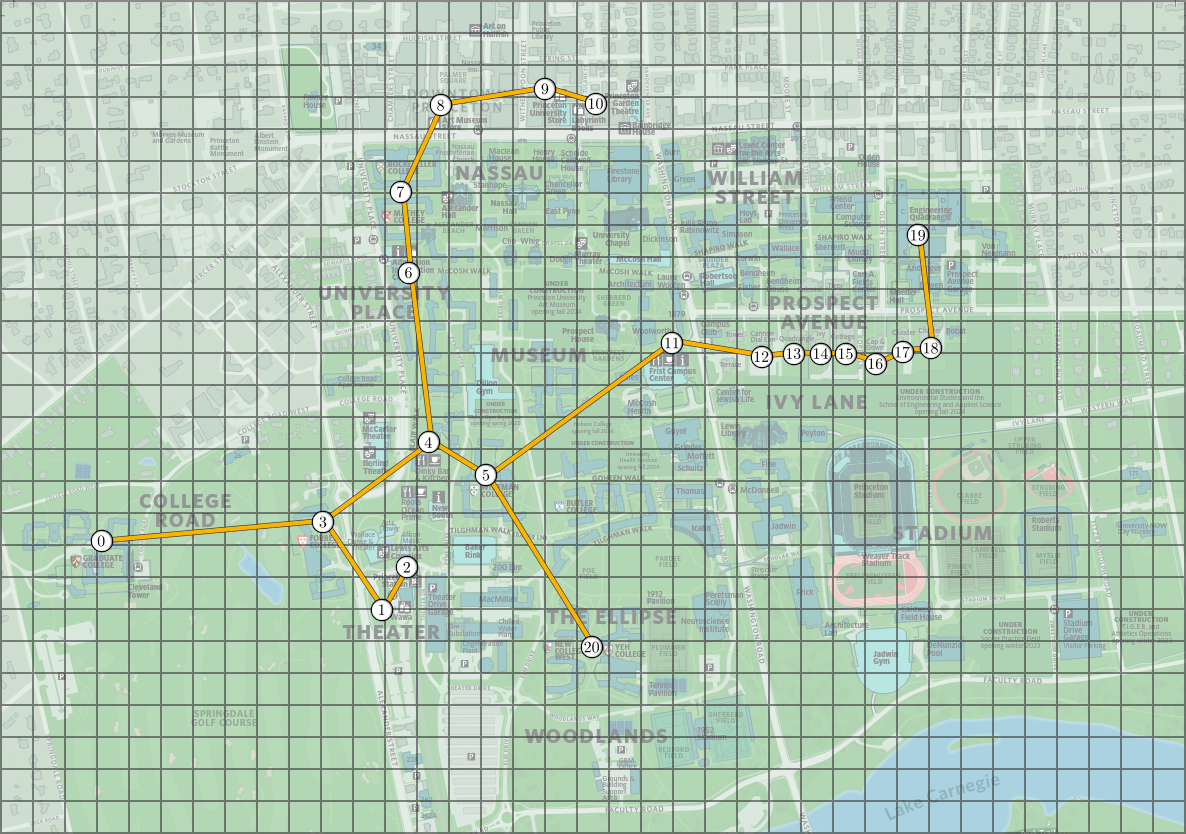

With the clusters above, we can reduce the dimension of the transaction summaries by summing all of the entries corresponding to the same cluster, to obtain a new array with \(k\) elements. This is illustrated in the image below, where each color corresponds to a cluster obtained in the previous image example.
| 5 | 6 | 7 | 0 | 6 | 7 | 5 | 6 | 7 | 0 | 6 | 7 | 0 | 6 | 7 | 0 | 6 | 7 | 0 | 6 | 7 | Original |
| 5 | 26 | 24 | 39 | 7 | Reduced |
To help you test your code, we provide a file called princeton_locations.txt which starts with the number of locations and then contains one line per location, with the coordinates of the point. The points in this file follow the order of the above images (so again, the first point represent the "Graduate College," the leftmost one in the image). We also include a file princeton_locations_mst.txt that contains the edges of the minimum spanning tree of this graph.
Clustering Algorithm. Write a
class Clustering.java that implements the above
clustering algorithm, by implementing the following API:
public class Clustering {
// run the clustering algorithm and create the clusters
public Clustering(Point2D[] locations, int k)
// return the cluster of the ith point
public int clusterOf(int i)
// use the clusters to reduce the dimensions of an input
public int[] reduceDimensions(int[] input)
// unit testing (required)
public static void main(String[] args)
}
Note that the clusterOf() must return an integer
between \(0\) and \(k-1\) and clusterOf(i) should
only be equal to clusterOf(j) if and only if the
\(i\)th and \(j\)th points are in the same cluster.
Implementation requirements.
You should use
KruskalMST
and CC
to compute a minimum spanning tree and connected components.
Corner cases.
Throw an IllegalArgumentException if:
nullclusterOf() is not between \(0\) and \(m - 1\)reduceDimensions() has a length different from \(m\)Unit testing.
Your main() method must call each public constructor and method directly and
help verify that they work as prescribed (e.g., by printing results to standard output).
Performance requirements. Your implementation must achieve the following performance requirements:
clusterOf() should run in \(\Theta(1)\) time.reduceDimensions() should run in \(O(m)\) time.A weak learner is a machine learning model that performs marginally better than making random decisions. In the context of this assignment, this means predicting the right label more than \(50\%\) of the time. You will implement a model known as a decision stump, a really popular choice for weak learners.
A decision stump takes as input a sequence of \(n\) inputs, each
represented by an array of \(k\) integers (a dimension-reduced
transaction summary). This means that the input is a
2-dimensional \(n\) by \(k\) array of
integers input, where input[i][j] is
the amount of money spent at cluster j in reduced transaction summary
i. Each input is labeled with an integer, either
\(0\) or \(1\) (corresponding to clean
or fraud), which will be represented by an array of
\(n\) integers labels. Additionally, each input
also has a non-negative weight (this will be useful for the last
part of the assignment), which are represented by an array of
\(n\) doubles weights.
From the input data and labels, the decision stump "learns"
a predictor: a function that takes a single sample
(i.e. any array of \(k\) integers) as input and outputs a binary
prediction, either \(0\) or \(1\) (i.e. clean
or fraud). This predictor is a very simple function
which we describe in the following paragraphs. (note:
this description might seem a bit overwhelming at first. Try to
read the whole thing first and then study the image examples,
the visual representations will really help you understand the
description).
It is helpful to think about each input as a point in \(k\) dimensions, since it is simply a \(k\) dimensional array. With this perspective in mind, each decision stump corresponds to a (hyper)plane parallel to all of the axes except one. Given one such decision stump/(hyper)plane, it labels all points to one side of that plane as \(0\) and points on the other side as \(1\). To describe an (hyper)plane one needs to define three quantities: a dimension predictor \(d_p\), a value predictor \(v_p\) and a sign predictor \(s_p\).
The dimension predictor is an integer between \(0\) and \(k - 1\) that represents the non-parallel dimension/coordinate of the input space. The value predictor is an integer represents where the input space is partitioned (i.e. where the hyperplane crosses its non-parallel axis). The sign predictor is an integer, either \(0\) or \(1\), representing in which direction to partition space, i.e. which side of the plane gets labeled as \(0\) or \(1\).
Given an input point \(sample\) a decision stump with parameters \(d_p\), \(v_p\) and \(s_p\) applies the following labeling: if \(s_p = 0\) then the decision stump predicts \(0\) if \(sample[d_p] \leq v_p\) and \(1\) otherwise. Else, if \(s_p = 1\) then the decision stump reverses the prediction: \(1\) if \(sample[d_p] \leq v_p\) and \(0\) otherwise.
See the images below for an example with \(n = 8\) inputs of dimension \(k = 2\), where dimensions 0 and 1 correspond to the the x and y axes, respectively. Blue squares correspond to the label \(0\) and red circles to the label \(1\). The line in the image corresponds to a decision stump with parameters \(d_p = 1\), \(v_p = 4\) and \(s_p = 1\), and the resulting labeling is: points above the line are labeled as \(0\) and points on the line or below the line are labeled as \(1\).
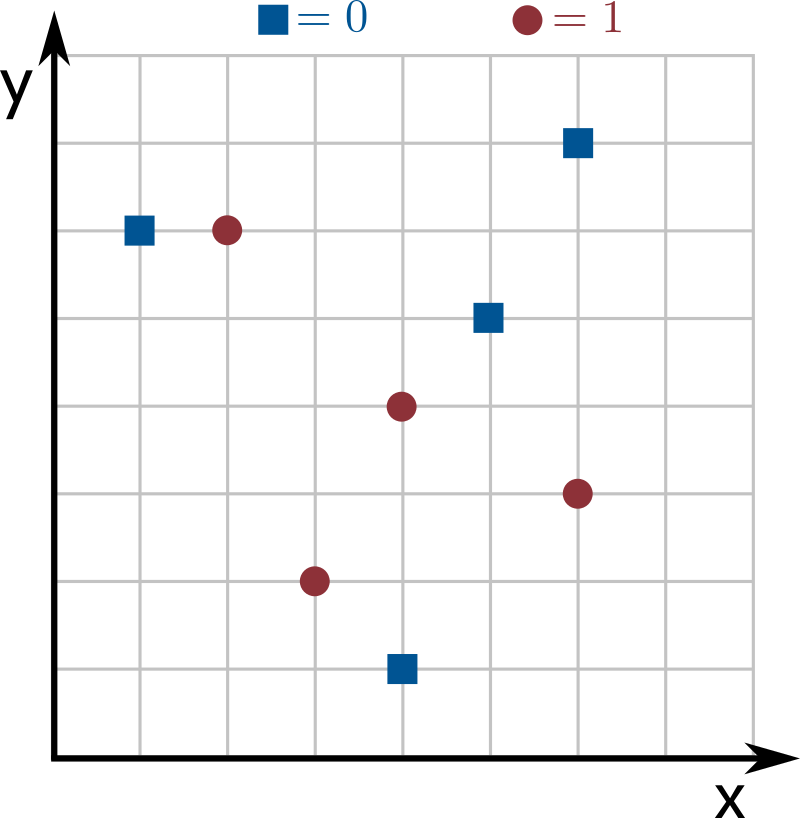

Your goal is to find the decision stump that best represents the input data (we call this step training the model). This means finding the values of \(d_p\), \(v_p\) and \(s_p\) that maximize the weight of correctly classified inputs, i.e. maximizing the sum of the weights of the inputs such that their predicted label matches the actual input label.
In the image above, suppose that all the points have weight \(1\). Then, the weight of correctly classified inputs by the given decision stump is \(6\) (all points are correctly classified except for one blue square and one red circle). Since no other decision stump mislabels less than 2 points, this one is optimal.
Weak Learner. Write a
class WeakLearner.java that implements the above
weak learner, by implementing the following API:
public class WeakLearner {
// train the weak learner
public WeakLearner(int[][] input, double[] weights, int[] labels)
// return the prediction of the learner for a new sample
public int predict(int[] sample)
// return the dimension the learner uses to separate the data
public int dimensionPredictor()
// return the value the learner uses to separate the data
public int valuePredictor()
// return the sign the learner uses to separate the data
public int signPredictor()
// unit testing (required)
public static void main(String[] args)
}
Corner cases.
Throw an IllegalArgumentException if:
null.input, weights, labels or sample are incompatible.weights are not all non-negative.labels are not all either \(0\) or \(1\).Unit testing. Your main() method
must call each public constructor and method directly and help
verify that they work as prescribed (e.g., by printing results
to standard output).
Performance requirements. Your implementation must achieve the following performance requirements:
dimensionPredictor(), valuePredictor(), signPredictor()
and predict() should run in \(\Theta(1)\)
time.Note: it's very easy to miss some corner cases in your implementation of this class. To debug your code using good test cases, read the checklist section on testing.
As the name suggests, the weak learner is not a very interesting model. So you will implement a better one using a technique called boosting, which is a term that describes algorithms that take weak learners and improve (boost) their quality. In this assignment you will implement a simplified version of an algorithm called AdaBoost (short for Adaptive Boosting), which is an application of the multiplicative weights algorithm.
The input is again a sequence of \(n\) labeled transaction
summaries (an \(n\) by \(m\) integer array input),
the \(m\) map locations (an array of
\(m\) Point2D), as well as an integer \(k\)
representing the number of clusters to cluster the locations
into. You should start by creating a Clustering
object so you can map transaction summaries into arrays of
length \(k\), using the dimensionality reduction method. From
now on, we will use the word input to refer to the reduced transaction
summaries, i.e. the arrays resulting from applied the
dimensionality reduction method to the original transaction
summaries.
AdaBoost is a version of multiplicative weights where the
input points are the experts. The algorithm assigns a
weight to each input point, represented as a double
array of length \(n\). This array is normalized, so that the sum
of its elements is always \(1\). Initially, the weights should
all be set to the same value: \(1 / n\).
The boosting algorithm works in steps or iterations. Each iteration should do the following:
We double the weight of mislabeled inputs to force the algorithm to try harder to predict them correctly in future iterations.
Given a sample (i.e. an \(m\) dimensional integer array corresponding to a new transaction summary) to make a prediction on, the boosting model should output the majority vote over the predictions given by the weak learner created in each iteration. This means you should use each weak learner created in each iteration to label the sample point, and then output the label that was predicted the most. In case of a tie, output \(0\). Note that a sample needs to be reduced before you can apply the model.
Boosting Algorithm. Write a
class BoostingAlgorithm.java that implements the above
boosting algorithm, by implementing the following API:
public class BoostingAlgorithm {
// create the clusters and initialize your data structures
public BoostingAlgorithm(int[][] input, int[] labels, Point2D[] locations, int k)
// return the current weight of the ith point
public double weightOf(int i)
// apply one step of the boosting algorithm
public void iterate()
// return the prediction of the learner for a new sample
public int predict(int[] sample)
// unit testing (required)
public static void main(String[] args)
}
Corner cases.
Throw an IllegalArgumentException if:
null.input, labels, locations
or sample are incompatible.labels are not all either \(0\) or \(1\).Unit testing. We provide you with some code to
help you test your Boosting.java
implementation. See the section on "Using the learners" below.
Performance requirements. Your implementation must achieve the following performance requirements:
weightOf() should run in \(\Theta(1)\) time.predict() should call the
WeakLearner's predict() method \(T\) times and the
Clustering's reduceDimensions() method once, where
\(T\) is the number of iterations done so fariterate() should create one WeakLearner object and then take \(O(n)\) time.A classical way of testing machine learning models is by partitioning labeled data into two data sets: a training and a test data set. The model is trained using the training data, and then it is tested on the test data set. We assess the quality of the model using a very simple metric called accuracy: the fraction of correct predictions. This metric can be used on the training, test or all inputs.
We provide several files that have been pre-partitioned into
training and test data sets, named accordingly. Below is a
sample client to test the BoostingAlgorithm.java
model. It takes two filenames (training and test data set
files), an integer \(k\) (the number of clusters for
dimensionality reduction), and an integer \(T\) (the number of
iterations of the boosting algorithm) as command-line
arguments. It trains the model on the training data set and
calculates the accuracy in the training and test data sets. It
uses a class called DataSet.java that is provided
in the project zip file.
public static void main(String[] args) {
// read in the terms from a file
DataSet training = new DataSet(args[0]);
DataSet testing = new DataSet(args[1]);
int k = Integer.parseInt(args[2]);
int T = Integer.parseInt(args[3]);
int[][] trainingInput = training.getInput();
int[][] testingInput = testing.getInput();
int[] trainingLabels = training.getLabels();
int[] testingLabels = testing.getLabels();
Point2D[] trainingLocations = training.getLocations();
// train the model
BoostingAlgorithm model = new BoostingAlgorithm(trainingInput, trainingLabels,
trainingLocations, k);
for (int t = 0; t < T; t++)
model.iterate();
// calculate the training data set accuracy
double training_accuracy = 0;
for (int i = 0; i < training.getN(); i++)
if (model.predict(trainingInput[i]) == trainingLabels[i])
training_accuracy += 1;
training_accuracy /= training.getN();
// calculate the test data set accuracy
double test_accuracy = 0;
for (int i = 0; i < testing.getN(); i++)
if (model.predict(testingInput[i]) == testingLabels[i])
test_accuracy += 1;
test_accuracy /= testing.getN();
StdOut.println("Training accuracy of model: " + training_accuracy);
StdOut.println("Test accuracy of model: " + test_accuracy);
}
To help you test your code, we provide two data sets, one called princeton_training.txt and one called princeton_test.txt. Both use the locations from the map described in the beginning of the assignment, and the inputs and labels were generated using a simulation. Here is one example run of the previous client with the model you implemented, and the output we obtained:
~/Desktop/fraud> java-algs4 BoostingAlgorithm princeton_training.txt princeton_test.txt 5 80 Training accuracy of model: 0.9625 Test accuracy of model: 0.7375
Note: your code might have slightly different
accuracy values, since your weak learner implementation might
tie break between decision stumps with the same weight
differently. The training accuracy should be
around 0.95 and the test accuracy should be
around 0.7.
Using this testing framework you will have to run some experiments and document them in the readme.txt (the file contains more details on what you should do).
Submission.
Submit only Clustering.java, WeakLearner.java and BoostingAlgorithm.java.
We will supply algs4.jar.
You may not call library functions except those in
those in java.lang, java.util, and algs4.jar.
Finally, submit readme.txt
and acknowledgments.txt
files and answer the questions.
Grading.
file points Clustering.java8 WeakLearner.java20 BoostingAlgorithm.java8 readme.txt4 40
Reminder: You can lose up to 4 points
for breaking style principles and up to 2
points for inadequate unit
testing.