Project 2: Non-Preemptive Kernel
Overview
With the bootup mechanism from the first project, we can start developing an operating system kernel. The main goal of this project is to extend the provided kernel to support multiprogramming. More specifically, you will:
- Implement a non-preemptive scheduler
- Perform context switches between threads and processes in Assembly
- Measure the cost of switching contexts
- Implement basic mutual exclusion
Although the kernel will be very primitive, you will be dealing with several core mechanisms and applying techniques that are important for building more advanced, multiprogrammed operating systems in the future.
The kernel of this project and future projects supports both processes and threads. Note that the processes in this project are different from those in traditional operating systems (like Unix). Our processes have their own protection domains, but they share a flat address space. In the future, we will be providing processes with separate address spaces. Our threads are kernel level threads that always share the same address space with the kernel; they will never run in user mode. The kernel threads are linked together with the kernel, subsequently they can access kernel data and functions directly. On the other hand, processes use the single entry-point mechanism described in the lecture.
Students have traditionally found this project to be more complex than the the first, so please begin now and work at a steady pace.
Design Review
Please cover these points at your design review:
- Process Control Block: What will be in your PCB and what will it be initialized to?
- Context Switching: How will you save and restore a task's context? Should anything special be done for the first task?
- Processes: What, if any, are the differences between threads and processes and how they are handled?
- Mutual exclusion: What's your plan for implementing mutual exclusion?
- Scheduling: Assuming that the threads below are put on the ready queue in order of their names and execution starts at Thread 1, how will execution unfold?
- Thread 1
lock_init(&lock);
lock_acquire(&lock);
do_yield();
lock_release(&lock);
do_exit();
- Thread 2
while(1)
{
do_yield();
}
- Thread 3
do_yield();
lock_acquire(&lock);
lock_release(&lock);
do_exit();
- Thread 4
lock_acquire(&lock);
lock_release(&lock);
do_exit();
Use the
signup sheet to schedule a time to see a TA in the fishbowl.
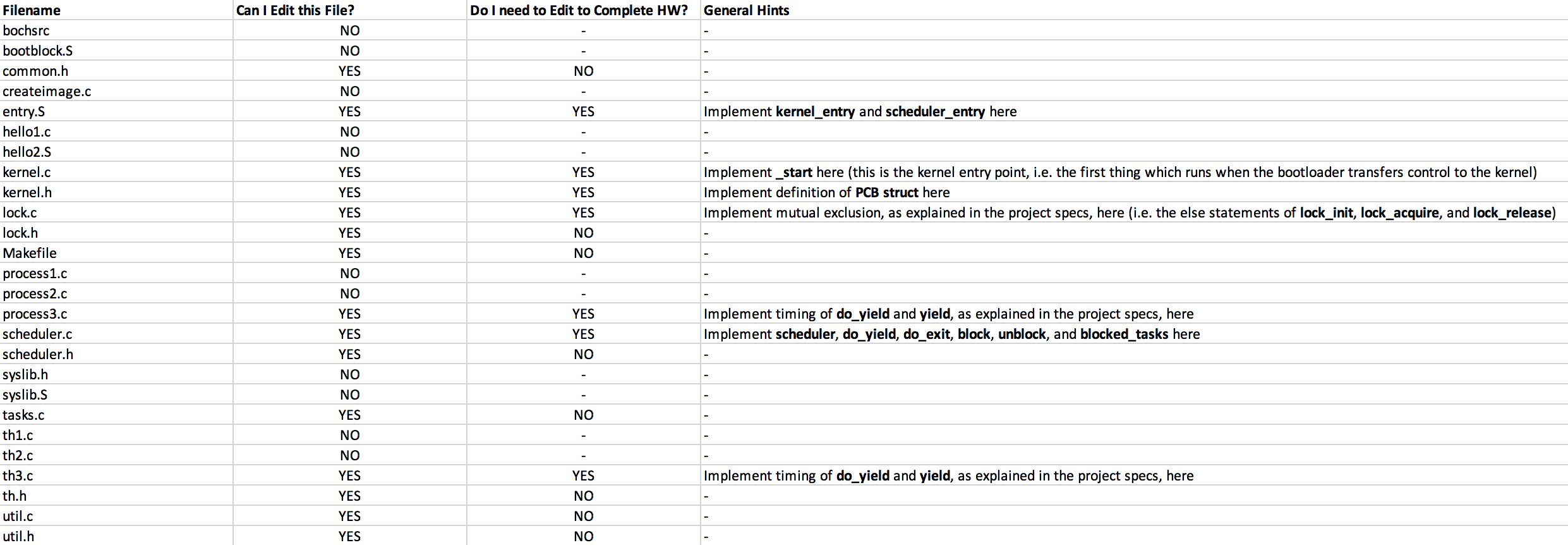
Getting Started
Use the start code which you can get from Blackboard or the fishbowl file server. Compiling this project is tricky, so we have provided the
Makefile. If you type
make (or use the
all target) it will compile all sources and prepare an image,
floppy.img, for use with
bochs. We've also supplied a configuration file,
bochsrc, that instructs
bochs to use this image as a floppy. A make target,
boot, is provided in the
Makefile to load the image onto your USB stick if you'd like to test on a real machine, but make sure it is cat'ing to the correct path before using.
The kernel
proper consists of a collection of kernel threads. These threads run in the
most privileged protection ring, and their code is part of the kernel loaded by
the boot block. Kernel threads share a flat address space, but they do not
share register values or stacks.
After the boot block has loaded the kernel, it calls the function
kernel.c:_start(). This function performs the setup necessary to run
the tasks listed in
tasks.c by initializing process control blocks
(PCBs) for each one. You are encouraged to allocate space for the PCBs
statically with
pcb_t pcbs[NUM_TASKS]. Make sure to loop on
NUM_TASKS when setting up PCBs as the number of tasks may be different
during testing.
Threads only run in one context: the kernel. Processes have two contexts: user
and kernel. You have an option in this project to decide how you want to deal
with this. One option is to make room in your PCB for both contexts. The other
option is to only leave room for one context and lose any kernel context for
each process after crossing the user-kernel boundary. This is ok because there
is not state that needs to be kept within the kernel for processes. However, if
you choose to explicity save both, it is ok to "waste" space in the PCB for
threads that won't use the user context area.
Stacks are
STACK_SIZE bytes big and are allocated contiguously at
increasing addresses starting with
STACK_MIN. You may use the macro
common.h:ASSERT([assertion]) to enforce the invariant that all stacks
lie in the interval
STACK_MIN exclusive to
STACK_MAX
inclusive.
Since you are writing a non-preemptive scheduler, kernel threads run without
interruption until they yield or exit by calling
scheduler.c:do_yield() or
scheduler.c:do_exit(). These
functions in turn call
entry.S:scheduler_entry(), which saves the
contents of the general purpose and flags registers in the PCB of the task that
was just running.
scheduler.c:scheduler() is then called to choose the
next task, after which the next task's registers are restored, and the task is
ret'd to.
scheduler.c:scheduler() chooses the next task to
run in a strict round-robin fashion, and in the first round, the tasks are run
in the order in which they are specified in
tasks.c.
Please make sure that if all the tasks have exited (in case
clock_thread is
not running, for example) your kernel doesn't
crash. You could loop in the scheduler printing out the fact that there are no
more tasks to run.
scheduler.c:scheduler() increments the global variable
scheduler.c:scheduler_count every time it runs. Do not change
this.
In future projects, processes will have their own protected address spaces
and run in a less privileged protection ring than the kernel. For now, however,
there are only slight differences between threads and processes. If you choose
to save both user and kernel contexts, processes will have two stacks: one user
stack, for the process proper, and one kernel stack, for the yield and
exit system calls made by the process. Moreover, process code is not
linked with the kernel, thus the need for the single entry-point mechanism (see
how syslib.S:kernel_entry is called).
There are two system calls: syslib.S:yield() and
syslib.S:exit(), which processes call. These correspond in principle
to the calls do_yield() and do_exit() that threads use.
Processes cannot invoke do_yield() and do_exit() directly
though because they don't know the addresses of these functions.
This project uses a dispatch mechanism to overcome the difficulty of processes
not knowing the addresses of do_yield() and do_exit().
kernel.h defines a spot in memory called ENTRY_POINT at which
_start() writes the address of the function label
kernel_entry (in entry.S) at run-time. When a process calls
yield() or exit() (in syslib.S), SYSCALL(i) (in the
same file) gets called with an argument that represents which system call the
caller wants (yield or exit), similar to how a number was stored in %ah
before initiating a BIOS interrupt. SYSCALL(i) in turn calls
kernel_entry, whose address was saved at ENTRY_POINT.
kernel_entry saves the process's context to its PCB and then transfers
control to either of the previously "unreachable" do_yield() or
do_exit() functions. Like threads, something must restore the
processes' context after it is chosen to run again by
scheduler.
The call graph for task saving can seem a little complicated, so I've made the
following ASCII call graph diagrams:
Threads
do_yield (scheduler.c) -> scheduler_entry (entry.S) -> scheduler (scheduler.c)
do_exit (scheduler.c) -> " "
Processes
yield (syslib.S) -> kernel_entry (entry.S) -> do_yield (scheduler.c)
exit (syslib.S) -> " -> do_exit (scheduler.c)
lock.c contains three functions for use by kernel threads:
lock_init(l), lock_acquire(l), and lock_release(l).
lock_init(l) initializes lock l; initially no thread holds
the specified lock. In the event an uninitialized lock structure is passed to
the other functions, the results are up to you. lock_acquire(l) must
not block the thread that called it when no other thread is holding l.
Threads call lock_acquire(l) to acquire lock l. If no
thread currently holds l, it marks the lock as being held and returns.
Otherwise it uses scheduler.c:block(...) to indicate to the scheduler
that the thread is now waiting for the lock and should be put on the blocked
queue. If there are one or more threads on the blocked queue when
lock_release(l) is called by the thread holding the lock, the lock
remains locked and the thread at the head of the blocked queue is put on the
ready queue at the back, through a regular enqueue operation. If no threads are
waiting, it marks the lock as being not held and returns. The results of a
thread attempting to acquire a lock it already holds or to release a lock it
doesn't hold are up to you.
We have put a non-conforming implementation of mutual exclusion in
lock.c so that you can write and test the kernel threads part in
isolation. When you are ready to test your own implementation, change the
constant SPIN in lock.c to FALSE.
Note: your lecture notes describe how to synchronize access to the fields
associated with a lock. Since there is no preemption, if
lock_acquire(l) and block() don't call do_yield() in
the middle of manipulating data structures, you don't need to worry about race
conditions while these functions do their job. In particular, it is not
necessary to protect the scheduler data structures with a test-and-set
lock.
The function
util.c:get_timer() returns the number of instructions
that have been executed since boot. Using
util.c:print_int() and
util.c:print_str(), use the first line of the display to show the
number of cycles required by
do_yield and
yield using
thread4 and
thread5 in
th3.c and
_start in
process3.c respectively. Do
not time how long
do_exit,
exit,
if statements,
print_str, or
print_int take.
The measurement tasks should only print out their measurements once. The
numbers do not need to be stated in the README.
Checklist
Extra Credit
For extra credit, write a fair
scheduler. This means that the scheduler always chooses as the next task to run
the one that has had the least amount of time on the CPU thus far. Do
not include the time it takes to do a context switch when keeping track
of run time thus far. Prove that your scheduler is fair by writing tasks that
show execution time on the CPU is fair to within the longest interval between
yields.
Provide a way to turn the extra credit on and off and tell how that is done in
your README. Leave the extra credit off by default.
Hints
(Borrowed from previous years. Hints will be updated as questions come out from office hours / design reviews.)
Grading Rubric
| Description |
Points |
| Design review |
5 |
| OS can start a single task |
2 |
| do_yield and yield save and restore contexts correctly |
3 |
| Without locks, scheduler obeys FIFO order |
1 |
| OS can unfold execution for the 4 threads in design review correctly |
2 |
| Your lock can guarantee mutual exclusion and FIFO order for locks (that is, the thread acquire()ing the lock earlier gets it earlier) |
2 |
| th3.c and process3.c time JUST how long a do_yield or yield takes, respectively |
1 |
| OS can successfully load and run all tasks provided in the start code |
4 |
| Total |
20 |
| Extra Credit |
1 |
Glossary
- address line 20
- When PCs boot up, addresses 0x100000 to 0x1fffff are aliases for 0x00000 to 0xfffff to accommodate badly written real mode programs. Programs that use more than one megabyte of memory must disable this behavior. See http://www.win.tue.nl/~aeb/linux/kbd/A20.html.
- kernel mode
- Synonym for protection ring 0.
- process control block
- The process control block (PCB) contains all of the state the kernel needs to keep track of a process or kernel thread.
- protected mode
- In (16-bit) real mode, an address ds:si refers to byte 16*ds + si. In 32-bit protected mode, the segment registers contain offsets into the global descriptor table, whose entries control the translation of memory accesses into physical addresses. The boot block provided to you sets up the global descriptor table and segment registers so that no translation is applied; you can ignore the segment registers for this project. See http://www.internals.com/articles/protmode/introduction.htm.
- protection ring
- Intel processors since the 286 have four privilege levels, ring 0 through ring 3. Ring 0 is the most privileged; ring 3 is the least. Typically the kernel runs in ring 0, and user processes run in ring 3. For this project, all processes run in ring 0.
- system call
- In modern operating systems, processes are enjoined from accessing memory that they do not own. System calls are how processes communicate with the kernel. Typically, the process writes the system call number and its arguments in its own memory, and then it transfers control to the kernel with a special kind of far call. The kernel then performs the desired action and returns control to the process.
- task
- Following Linux, we use "task" to mean process or kernel thread.