

Due Sunday Nov 3 at midnight
This lab is meant to show you how Python programming might be useful in the humanities and social sciences. As always, this is a small taste, not the whole story, but if you dig in, you'll learn a lot, and you might well get to the point where you can write useful programs of your own.
You can use ChatGPT or the like to help you with syntax, suggest functions, explain how to use them, and so on, but you must include in your submission a complete description of what you did with these tools. Please don't just ask ChatGPT to do the lab for you.
This lab is newish, so there are sure to be murky bits and rough edges. Don't worry about details, since the goal is for you to learn about a useful technology, but let us know if something is confused or confusing.
Please read these instructions all the way through before beginning the lab.
Do your programming in small steps, and make sure that each step works before moving on to the next. Pay attention to error messages from the Python compiler; they may be cryptic and unfamiliar, but they do point to something that's wrong. Searching for error messages online may also help explain the problem; this is also a place where LLMs can be useful.
Most Python programming uses libraries of code that others have written, for an enormous range of application areas. This lab is based on two widely used libraries: the Natural Language Toolkit (NLTK), which is great for processing text in English (and other languages), and Matplotlib, which provides lots of ways to plot your data.
NLTK is documented in an excellent free online book called Natural Language Processing with Python, by Steven Bird, Ewan Klein, and Edward Loper. The book alternates between explanations of basic Python and illustrations of how to use it to analyze text. We will use only a handful of NLTK's features, primarily ones found in the first chapter, but you should skim the first three or four chapters to get a sense of what else NLTK can do for you.
You are welcome to use other libraries as well. In particular, spaCy ("industrial-strength natural language processing in Python") is a good complement to NLTK. This lab is meant to encourage you to experiment. We're much more interested in having you learn something that might help you in the future than forcing you through a specific sequence of steps.
In the last lab, you uploaded a local file to make it accessible to Colab. In this lab, you will load a file from the Internet directly into your Colab notebook.
Let's access a book from the Internet and do some experiments. I've chosen Pride and Prejudice from Project Gutenberg, but you can use anything else that you like. It can be a help if you're familiar with whatever document you choose so you can think of questions to explore and spot places where something doesn't look right, though you might also decide to look at material that isn't too familiar.
In case it wasn't obvious, don't use Pride and Prejudice. Pick something else.
In this part, please follow along with Austen or a book of your own. Later on you will get to do further explorations with your chosen text. You might find that some of the outputs differ from what is shown here; it seems that even the sacred Austen text is subject to updates over time.
In the rest of the lab,
we will use pink blocks like this for code
and green blocks like this for output produced by that code.
Start a new Code block for each of the pink blocks. That will help you keep track of where you are, and it's more efficient than repeatedly downloading the original text.
This sequence of Python statements fetches the whole text, including boilerplate at the beginning and end:
from urllib import request
url = "https://www.gutenberg.org/cache/epub/42671/pg42671.txt"
response = request.urlopen(url)
raw = response.read().decode('utf8') # reads all the bytes of the file in utf-8, a form of Unicode
In Colab, this would look like this before it has been run.
After it has been run, the variable raw contains a long string of Unicode characters. We can compute how long the text is, and we can print some or all of it:
print(len(raw)) print(raw[2295:2685])
725079 It is a truth universally acknowledged, that a single man in possession of a good fortune, must be in want of a wife. However little known the feelings or views of such a man may be on his first entering a neighbourhood, this truth is so well fixed in the minds of the surrounding families, that he is considered as the rightful property of some one or other of their daughters.
The expression raw[start:end] is called a slice; it's a convenient feature of many programming languages. It produces a list containing the characters from position start to position end-1 inclusive, so in the case above, it provides the characters in positions 2240 to 2669. If you omit start, the slice starts at the beginning (character 0), and if you omit end, the slice ends at the last character (one position before end). Negative numbers count backwards from the end, so [-500:] is the last five hundred characters. You can experiment with statements like
print(raw[0:150]) print(raw[-300:])to figure out where the book text begins and ends. (Remember binary search?)
The start and end positions for this specific book were determined by experiment, which is not very general, though it's helpful for getting started. If you know what you're looking for, it's more effective to use the find function to locate the first occurrence of some text:
start = raw.find("It is a truth")
end = raw.find("wife.") # Which wife do you get?
print(raw[start:end+5]) # Why +5?
It is a truth universally acknowledged, that a single man in possession of a good fortune must be in want of a wife.
Use your own numbers and text to find the beginning and end of the real text in your chosen book. Gutenberg books have a lot of boilerplate at both ends. The extra material at the end appears to be consistently marked with
*** END OF THE PROJECT GUTENBERG EBOOKAgain, we could find the end by experiment, but it's easier to let Python do the work:
end = raw.find("*** END OF THE PROJECT GUTENBERG EBOOK")
print(raw[end-500:end])
re always on the most intimate terms. Darcy, as well as Elizabeth, really loved them; and they were both ever sensible of the warmest gratitude towards the persons who, by bringing her into Derbyshire, had been the means of uniting them. [...] Transcriber's note: Spelling and hyphen changes have been made so that there is consistency within the book. Any other inconsistencies with modern spellings have been left as printed.There's still some noise, but we're close to having the actual text.
Combining all this, we can define a new variable body that contains exactly the text of the book:
start = raw.find("It is a truth")
end = raw.find("*** END OF THE PROJECT")
body = raw[start:end-270]
body = body.strip() # remove spaces at both ends
len(body)
print(body[:100], "[...]", body[-100:])
It is a truth universally acknowledged, that a single man in possession of a good fortune, must be [...] itude towards the persons who, by bringing her into Derbyshire, had been the means of uniting them.
You can get an approximate word count by using the split function to split the text into a list of "words," which are the alphanumeric parts of the text that were separated by blanks or newlines. The result is an list of words, indexed from 0. The len function returns the number of items in the list, and again you can use the slice notation to see parts of the list.
words = body.split() # creates a list "words" by splitting on spaces and newlines print(len(words)) # len(list) is the number of items in the list print(words[0:10])
121804 ['It', 'is', 'a', 'truth', 'universally', 'acknowledged,', 'that', 'a', 'single', 'man']
Chapter 1 of the NLTK book uses a database of text materials that its authors have collected, and a variety of interesting functions that we won't try. You can certainly explore that, but here we are going to use our own data, which is a bit simpler and less magical, and requires only a small subset of what NLTK offers.
Before you can use functions from the NLTK package, you have to import it like this:
import nltk
words = nltk.tokenize.wordpunct_tokenize(body) # produces a list, like split() print(len(words)) print(words[0:10])
144879 ['It', 'is', 'a', 'truth', 'universally', 'acknowledged', ',', 'that', 'a', 'single']Notice that the number of "words" is quite a bit larger than the value computed by a simple split, and the words are subtly different as well: look at the word acknowledged and you'll see that the comma in the first occurrence is now a separate item. Separating punctuation in this way might well explain the difference in counts.
Of course, a comma is not a word, but that's a problem for another day.
Now let's look at vocabulary, which is the set of unique words. This doesn't really need NLTK; we can use functions that are part the standard Python library. The function set collects the unique items, and the function sorted sorts them into alphabetic order.
uniquewords = set(words) # the set function collects one instance of each unique word print(len(uniquewords)) sortedwords = sorted(uniquewords) # sort the words alphabetically print(sortedwords[:20])
6875
['!', '!"', '!"--', '!)', '!--', '"', '"\'', '"--', '&', "'", "',", '(', ')', '*', ',', ',"', ',"--', ",'", ",'--", ',)']
It's clear that the punctuation is throwing us off the track,
so let's write code to discard it. We'll use a for
loop here, though Pythonistas would use the more compact but
less perspicuous code that has been commented out.
# realwords = [w.lower() for w in words if w[0].isalpha()]
realwords = [] # create an empty list (no elements)
for w in words: # for each item in "words", set the variable w to it
if w.isalpha(): # if the word w is alphabetic
realwords.append(w.lower()) # append its lowercase value to the list
rw = sorted(set(realwords))
print(len(rw))
print(rw[:10])
The result is a lot more useful, and the number of real words is
smaller now that the punctuation has been removed:
6268 ['a', 'abatement', 'abhorrence', 'abhorrent', 'abide', 'abiding', 'abilities', 'able', 'ablution', 'abode']We can look at other parts of the list of words, such as the last ten words:
print(rw[-10:])
['younge', 'younger', 'youngest', 'your', 'yours', 'yourself', 'yourselves', 'youth', 'youths', 'à']and, with a loop, some excerpts from the list:
for i in range(0,len(rw),1000): # range produces a list of indices from 0 to len in steps of 1000 print(rw[i:i+10]) # for each index, print a slice that starts there
['a', 'abatement', 'abhorrence', 'abhorrent', 'abide', 'abiding', 'abilities', 'able', 'ablution', 'abode'] ['comes', 'comfort', 'comfortable', 'comfortably', 'comforted', 'comfortless', 'comforts', 'coming', 'command', 'commanded'] ['escaped', 'escaping', 'especially', 'esq', 'essence', 'essential', 'essentials', 'establish', 'established', 'establishment'] ['inmate', 'inmates', 'inn', 'innocent', 'innocently', 'inns', 'inoffensive', 'inquire', 'inquired', 'inquiries'] ['pay', 'paying', 'payment', 'peace', 'peaches', 'peak', 'peculiar', 'peculiarities', 'peculiarity', 'peculiarly'] ['settlement', 'settlements', 'settling', 'seven', 'several', 'severe', 'severest', 'severity', 'sex', 'sha'] ['visible', 'visit', 'visited', 'visiting', 'visitor', 'visitors', 'visits', 'vivacity', 'vogue', 'voice']
nltk.download('stopwords') # has to be done once
text = nltk.Text(words)
text.collocations()
Lady Catherine; Miss Bingley; Sir William; Miss Bennet; every thing; Colonel Fitzwilliam; dare say; Colonel Forster; young man; every body; thousand pounds; great deal; young ladies; Miss Darcy; ---- shire; Miss Lucas; went away; next morning; said Elizabeth; depend uponWe removed "stopwords", that is, frequently used but likely irrelevant words like "a", "the", "of", and so on. If we had not done so, there would be more uninteresting collocations like of the or and she.
text.concordance("Darcy")
Displaying 25 of 417 matches: the gentleman ; but his friend Mr . Darcy soon drew the attention of the room st between him and his friend ! Mr . Darcy danced only once with Mrs . Hurst an and during part of that time , Mr . Darcy had been standing near enough for he ess his friend to join it . " Come , Darcy ," said he , " I must have you dance ndsome girl in the room ," said Mr . Darcy , looking at the eldest Miss Bennet . Bingley followed his advice . Mr . Darcy walked off ; and Elizabeth remained tion , the shocking rudeness of Mr . Darcy . " But I can assure you ," she adde ook it immediately . Between him and Darcy there was a very steady friendship , haracter .-- Bingley was endeared to Darcy by the easiness , openness , ductili ed dissatisfied . On the strength of Darcy ' s regard Bingley had the firmest r e highest opinion . In understanding Darcy was the superior . Bingley was by no...
text.dispersion_plot(["Elizabeth", "Jane", "Lydia", "Kitty", "Mary"])This used to work but the implementation of this function was changed in December 2022, with the result that the names come out in the order Mary, Kitty, ..., with the wrong values attached.
You can fix this by inserting the following version of the dispersion_plot function, and changing the call of the function, like this:
import matplotlib.pyplot as plt
def dispersion_plot(text, words, ignore_case=False, title="Lexical Dispersion Plot"):
words = list(reversed(words))
word2y = {
word.casefold() if ignore_case else word: y
for y, word in enumerate(words)
}
xs, ys = [], []
for x, token in enumerate(text):
token = token.casefold() if ignore_case else token
y = word2y.get(token)
if y is not None:
xs.append(x)
ys.append(y)
_, ax = plt.subplots()
ax.plot(xs, ys, "|")
ax.set_yticks(list(range(len(words))), words)
ax.set_ylim(-1, len(words))
ax.set_title(title)
ax.set_xlabel("Word Offset")
return ax
dispersion_plot(text, ["Elizabeth", "Jane", "Lydia", "Kitty", "Mary"])
Just copy and paste and you should see something like this:
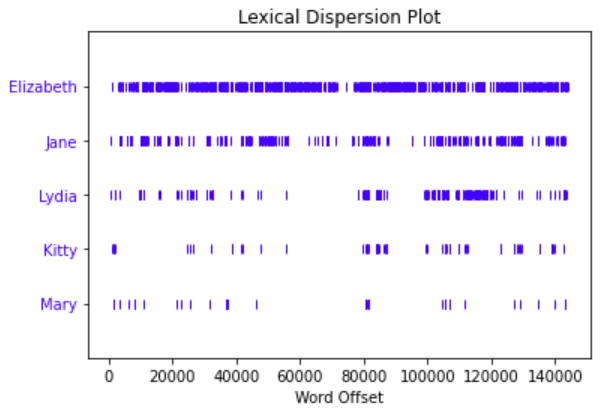
It's clear that Elizabeth is the main character, and Mary is a bit player. (For an alternative history, see The Other Bennet Sister, by Janice Hadlow, available in Firestone.)
import matplotlib fd = nltk.FreqDist(realwords) # fd is a variable that has multiple components print(fd.most_common(20)) # including some functions! fd.plot(20)
[('the', 4338), ('to', 4161), ('of', 3629), ('and', 3586), ('her', 2205), ('i', 2052), ('a', 1943), ('in', 1882), ('was', 1844), ('she', 1689), ('that', 1550), ('it', 1534), ('not', 1421), ('he', 1325), ('you', 1325), ('his', 1257), ('be', 1236), ('as', 1187), ('had', 1170), ('for', 1063)]
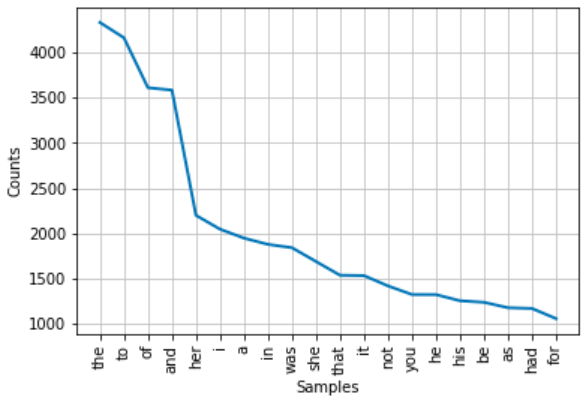
The numbers indicate the number of times each word occurs in the document; as might be expected, "the" is most common. We can also see how often the names of our hero and heroine appear:
print(fd['elizabeth'], fd['darcy'])
634 417
Your task is to repeat the experiments from Part 2, but this time with a different, book-length text from (ideally from Project Gutenberg). The process should be mostly the same, but make sure to choose a new document that is not Pride and Prejudice. The goal of the lab is for you to learn some more Python, see how it can be used for text analysis, and have fun along the way.
What else can you do that isn't listed here? Look at the NLTK book again for inspiration. Chapter 1 includes several ideas that we did not explore above, including the functions similar and common_contexts in section 1.3 to list words that appear in similar contexts, and a computation of unusually long words in section 3.2. There are also more frequency distribution functions in section 3.4.
Save your Colab notebook in a file called lab6.ipynb, using File / Download .ipynb. The .ipynb file should not be too large, say no more than a megabyte. To save space, delete the outputs of the various code sections before you download, since they can be recreated by re-running your code. We will experiment with your experiments by running your notebook, so please make sure it works smoothly for us. Get a friend to run through yours to see if it works for him or her.
Upload lab6.ipynb to Gradescope.
Don't upload anything to cPanel.