COS 429: Computer Vision, Fall 2013
Assignment 4: Object Classification

|
COS 429: Computer Vision, Fall 2013 |
|
Imagine that you have a life-log of images taken from your Google Glass once per minute throughout your entire life, and your goal is to create a computer system that can use those images to extend your memory -- i.e., a memex as described by Vannevar Bush in 1945. Your system should be able to answer queries like: "retrieve images containing the person I see now," "retrieve images from other times I visited the place I see now," "retrieve the page of notes related to the test question I see now," etc. (ok, not the last one).
Please write one or two paragraphs discussing what computational methods you suggest using to represent and search the images in your life-log (e.g., would your bag-of-words method be good?). Please keep in mind that most people visit the same places and do the same things every day, and so most of the images will be very similar, and small differences may make them worthy of a search result.
Please be as specific as possible, including a description of exactly how images are represented (X numbers for this, Y numbers for that, etc.) and how your search algorithm uses your proposed representation to find relevant images. You can assume that the query image is uploaded to "the cloud" instantaneously and all computation is done there. So, there is no need to worry about storage, processing, transmission, and power limitations of wearable devices.
Your goal for this part of the assignment is to write a MATLAB program to predict the basic-level category of an object shown in an image. The input will be a training set of images with class labels (e.g., airplane, butterfly, etc.), plus a set of test images. Your goal is to learn a classifier that can correctly predict the class label for each of the test images.
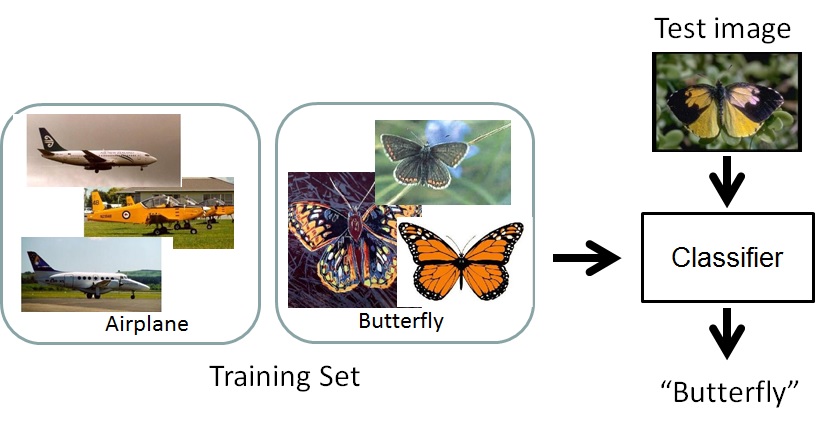
There are many ways to address this problem. Our approach will be to use a Naive Bayes classifier trained on a "bag of words" representation of the images. Specifically, we will learn the distribution of "codewords" appearing in each object class of the training set and then predict the most likely class for each test image based on its distribution of codewords.
The following is an overview of the steps you should take to build such a classifier and test it:
Step A: Training
[train_results] = train(basepath, class_names, options)Train a Naive Bayes classifier that predicts the object class depicted in an image based on distributions of codewords. The inputs to the algorithm are: 1) a "basepath" parameter that provides the name of the directory containing the training set of images, 2) a "class_names" parameter that provides a vector of class names, and 3) an "options" parameter that can be used to pass any parameters you wish.
The directory structure rooted at "basepath" can be assumed to have a subdirectory named after each class containing .jpg images with examples for that class. For example, if "basepath" is 'train_input' and classnames[1] is 'airplane', then you can expect that there is subdirectory named 'train_input/airplane' containing .jpg images of airplanes. Your procedure to train a classifier should contain the following steps:
- Select N patch locations from each training image (N=100). For this step, you might use random locations, corner feature locations, sift feature locations, or another method that you think might work well.
- Compute a patch descriptor for the local neighborhood around each patch location. For this step, you might use a sift descriptor, a "window" descriptor (e.g., an 11x11 window of luminance or color values), or any other representation that you think is best for this task.
- Compute a codebook representing a map from patch descriptors to "codewords," where a codeword is an integer indicating the ID of the cluster containing the given patch descriptor. For this step, you will probably want to use the k-means algorithm as implemented by the kmeans function in the MATLAB statistical toolbox to compute a set of k cluster centers (k=100). Then, the mapping from any patch descriptor to a cluster ID can be computed by finding the cluster whose center is closest in descriptor space (i.e., the cluster whose mean descriptor has minimal L2 difference from the given patch descriptor).
- Learn histograms of codewords for each object class:
For each class: For each training image in the class: For each patch: Find its codeword in the codebook, and increment a counter for that codeword's entry in a k-dimensional histogram for the class.- Return a structure, "train_results," containing the information needed to classify new images -- e.g., a MATLAB struct with the codebook and the histograms of codewords for each object class. The exact form of this struct is up to you.
Step B: Testing
[confusion_mat] = classify(basepath, class_names, train_results, options)Classify each image in the test set. As before, the directory structure rooted at "basepath" can be assumed to have a subdirectory named after each class containing .jpg images with example images of that class. You will predict an object class for each of the images in those subdirectories based on the bag-of-words classifer learned during the training phase and then measure how well your predictions match the true object classes indicated by the subdirectory names.
The result is a confusion matrix summarizing how often your algorithm classifies images correctly and what types of errors it makes. Specifically, if there are M object classes, the returned confusion matrix should have M rows and M columns, where the entry in the i-th column and j-th row equals the probability that a query for an image of class i yields a result of class j with your classifier. Higher values on the diagonal represent better classification rates, and strong off-diagonal entries indicate a confusion between two classes.
To implement the testing phase, you should do the following for each test image:
- Select N patch locations using the same procedure as you did during training.
- Compute a patch descriptor for each patch location using the same procedure as you did during training.
- Classify the image based on its distribution of codewords. For this step, you should use the Naive Bayes method as described in this document:
Set the (un-normalized) log-probability of each class to 0 For each of the N patches: Find the nearest codeword in the codebook, and add log(1 + the count of that codeword in the class's histogram) to the log-probability of each class Select the class with the Maximum A Posteriori (MAP) log-probability.- Update the confusion matrix.
Unlike previous assignments, we do not prescribe a particular method that you must use to implement the first two steps of the algorithm (selecting patch locations and computing patch descriptors). Rather, we ask that you make your own choices and then justify them in your writeup. Specifically, the "Programming Exercise" section of your writeup should include a description of the options you considered for computing patch locations and descriptors and the reasons you chose the ones you did. Though not required, you may want to test simple alternatives to provide evidence for your justification.
Part 3: Results and Analysis
Please use runme.m to train your classifier using the training set of images in the "train_input" subdirectory of cos429_assignment4.zip and then test it on images in the "test_input" subdirectory.
Please include results of your tests in a third section of your writeup titled "Results and Analysis." To facilitate your evaluations, runme() produces an image representing your computed confusion matrix and a file containing computed classification rates (fraction of correctly classified images). In addition to showing these results, please provide a short discussion of how well your algorithm worked on specific classes, why it succeeded or failed on some classes but not others, and what are its typical failure modes.
Getting Started
You should start from cos429_assignment4.zip, which provides the directory structure to follow in your submission, a template for your writeup (writeup/writeup.html), a set of training images (images_train/*.jpg), a set of test images (images_test/*.jpg), a simple template for the MATLAB functions you must implement (code/train.m and code/classify.m), a MATLAB library for computing sift feature descriptors (code/sift/*), and a script to ease creating results for your writeup (code/runme.m).You should fill in implementations of the required algorithms in the provided MATLAB files (and possibly create new ones), execute runme.m to produce your results, and complete your writeup.
Submitting Your Solution
Please submit your solution via the dropbox link here.
Your submission should include a single file named "assignment4.zip" with the following structure:
- A subdirectory named "
code" containing your source code. You should not change the API of the MATLAB functions provided, but you may add new MATLAB files as you see fit.- A subdirectory named "
output" containing files with the classification rates and confusion matrices produced by your program (should be produced automatically by runme.m).- A subdirectory named "
writeup" containing a file named "writeup.html" containing separate sections titled: (you can start from the template provided in the .zip file):
- Thought exercise: your answer to the question in Part 1.
- Programming exercise: a brief statement of what works and does not work in your implementation, plus a description of what algorithmic choices you made, why you chose them, and how they affected the results.
- Results and Analysis: display and discussion of results produced by your program.
- Conclusion: summary of your findings.
- Notes: any other comments, description of any assistance received and/or any discussions had with other students.
Please follow the general policies for submitting assignments, including the late policy and collaboration policy.